Poster Schedule
The program overview is available here.
AAMAS25 has 6 poster sessions, 2 sessions per day of the main conference (May 21 – 23), each running in parallel to a coffee break/demo session.
- Morning poster session: 10:00AM – 10:45AM each day
- Afternoon poster session: 3:45PM – 4:30PM (May 21 – 22), 3:15PM – 4:00PM (May 23)
In each session, at most 70 posters will be presented (for both accepted full papers and accepted extended abstracts), organized into 3 – 4 topical clusters based on the areas of interest detailed in the Call for Papers (Main Technical Track).
Poster information
- In each session, the poster presentation area will be divided among the respective topical clusters, with each poster occupying one poster slot in the section assigned to its cluster on a first come first serve basis. We will add detailed space allocation information to this page closer to the conference.
- Maximum poster dimensions: A0, which is approximately 46.8 inches tall by 33.1 inches wide (1189mm in height by 841mm in width). Portrait orientation is recommended.
- The posters for papers to be presented orally in TSn are typically assigned to PSn, n = 1, 2, …, 6.
- Useful information on poster printing is available here.
Location
All poster sessions will be held in the Ontario Exhibit Hall on the 3rd floor of the conference venue.
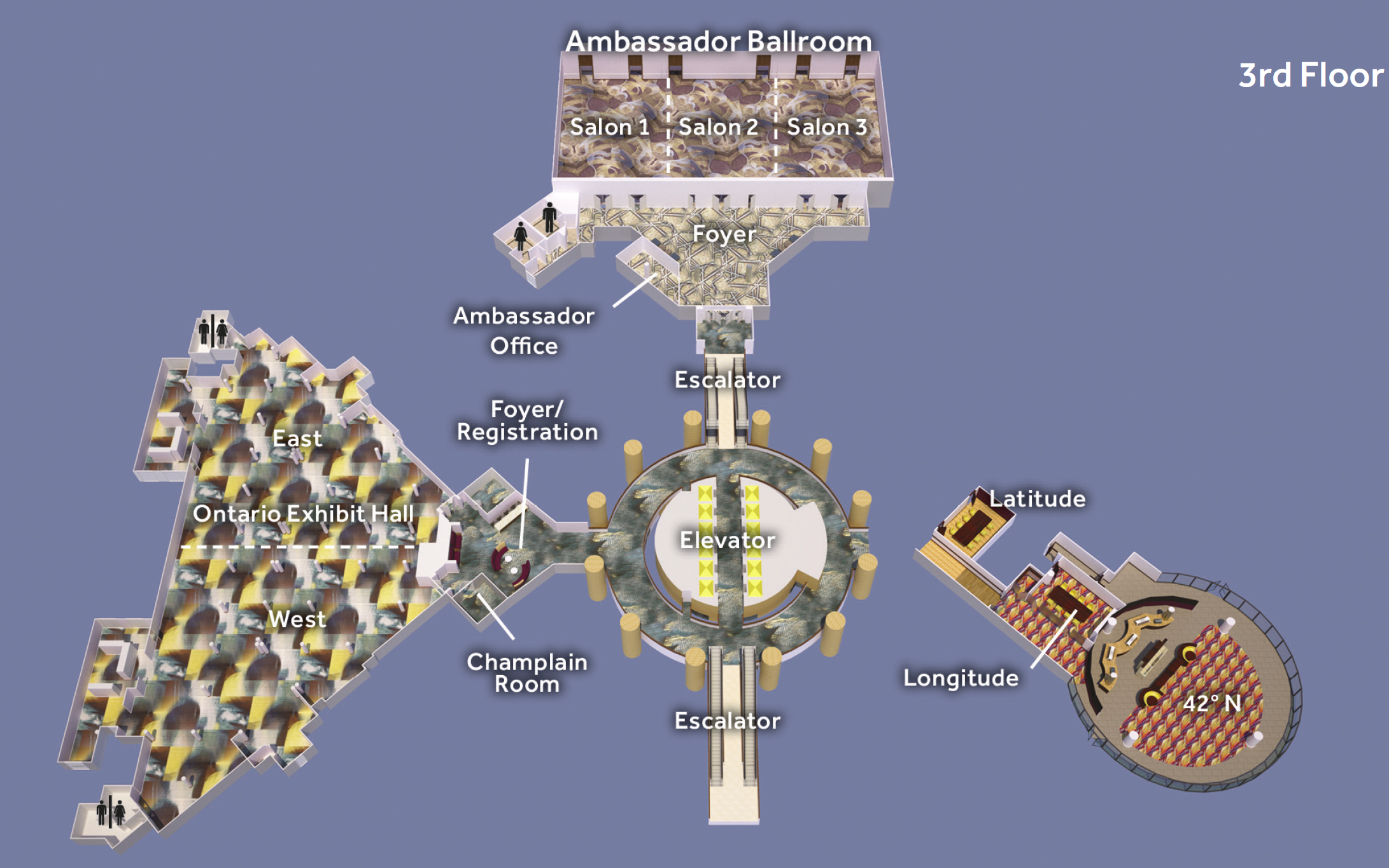{kind=link}
The assignment of sections of the hall to clusters will be announced before the relevant poster session during the conference.
Below we provide details of each session, including the names of the topical clusters and the number of posters in each cluster in parentheses next to the cluster name. Please click on the cluster name next to a black triangle to view the full list of all papers in that cluster.
Poster Session 1 (PS1): May 21 Morning
Date & Time: Wednesday, May 21, 10:00AM – 10:45AM
Total number of posters: 65
GTEP (22)
| ID | Title | Authors |
|---|---|---|
| 534 | Synergistic Traffic Assignment | Thomas Bläsius, Adrian Feilhauer, Markus Jung, Moritz Laupichler, Peter Sanders, Michael Zündorf |
| 517 | Minimizing Rosenthal’s Potential in Monotone Congestion Games | Vittorio Bilò, Angelo Fanelli, Laurent Gourvès, Christos Tsoufis, Cosimo Vinci |
| 420 | Fairness and Optimality in Routing | Sreenivas Gollapudi, Kostas Kollias, Alkmini Sgouritsa, Ali Kemal Sinop |
| 827 | Resource Task Games | Jessica L. Newman, Enrico Gerding, Enrico Marchioni, Baharak Rastegari |
| 870 | Selfish Behavior and Resource Competition in Multi-Agent Systems | Costas Courcoubetis, Antonis Dimakis |
| 470 | The Bakers and Millers Game with Restricted Locations | Simon Krogmann, Pascal Lenzner, Alexander Skopalik |
| 1029 | Smooth Information Gathering in Two-Player Noncooperative Games | Fernando Palafox, Jesse Milzman, Dong Ho Lee, Ryan Park, David Fridovich-Keil |
| 279 | Higher-Order Belief in Incomplete Information MAIDs | Jack Foxabbott, Rohan Subramani, Francis Rhys Ward |
| 314 | Soft Condorcet Optimization for Ranking of General Agents | Marc Lanctot, Kate Larson, Michael Kaisers, Quentin Berthet, Ian Gemp, Manfred Diaz, Roberto-Rafael Maura-Rivero, Yoram Bachrach, Anna Koop, Doina Precup |
| 939 | Eliminating Majority Illusion | Foivos Fioravantes, Abhiruk Lahiri, Antonio Lauerbach, Lluís Sabater, Marie Diana Sieper, Samuel Wolf |
| 739 | Why Instant-Runoff Voting Is So Resilient to Coalitional Manipulation: Phase transitions in the Perturbed Culture | François Durand |
| 602 | k-Approval Veto: A Spectrum of Voting Rules Balancing Metric Distortion and Minority Protection | Fatih Erdem Kizilkaya, David Kempe |
| 360 | The Metric Distortion of Randomized Social Choice Functions: C1 Maximal Lottery Rules and Simulations | Fabian Frank, Patrick Lederer |
| 112 | Candidate nomination for Condorcet-consistent voting rules | Ildikó Schlotter, Katarína Cechlárová |
| 579 | Condorcet Winners and Anscombe’s Paradox Under Weighted Binary Voting | Carmel Baharav, Andrei Constantinescu, Roger Wattenhofer |
| 16 | Adapting Beyond the Depth Limit: Counter Strategies in Large Imperfect Information Games | David Milec, Vojtech Kovarik, Viliam Lisý |
| 824 | Equilibrium selection via communication partition | Wei-Chen Lee, Alessandro Abate, Michael J. Wooldridge |
| 386 | Policies with Sparse Inter-Agent Dependencies in Dynamic Games: A Dynamic Programming Approach | Xinjie Liu, Jingqi Li, Filippos Fotiadis, Mustafa O. Karabag, Jesse Milzman, David Fridovich-Keil, ufuk topcu |
| 1262 | Pure Nash Equilibrium and Strong Nash Equilibrium Computation in Additive Aggregate Games | Jared Soundy, Mohammad T. Irfan, Hau Chan |
| 673 | The Costly Bargain: Economic Impacts of Price-Seeking Behavior in Aging Populations | Fuguang Chen, Alan Tsang |
| 464 | Social Ranking for Feature Selection | Laurent Gourvès, Stefano Moretti, Satya Tamby |
| 117 | Resource Allocation under the Latin Square Constraint | Yasushi Kawase, Bodhayan Roy, Mohammad Azharuddin Sanpui |
LEARN (11)
| ID | Title | Authors |
|---|---|---|
| 1347 | Enhancing Sub-Optimal Trajectory Stitching: Spatial Composition RvS for Offline RL | Sheng Zang, Zhiguang Cao, Bo An, Senthilnath Jayavelu, Xiaoli Li |
| 771 | A View of the Certainty-Equivalence Method for PAC RL as an Application of the Trajectory Tree Method | Shivaram Kalyanakrishnan, Sheel Shah, Santhosh Kumar Guguloth |
| 704 | Consistency Policy with Categorical Critic for Autonomous Driving | Xing Fang-CASIA, Qichao Zhang, Haoran Li, Dongbin Zhao |
| 461 | Leveraging Score-based Models for Generating Penalization in Model-based Offline Reinforcement Learning | Zeyuan Liu, Zhirui Fang, Jiafei Lyu, Xiu Li |
| 74 | Offline Goal-Conditioned Reinforcement Learning with Elastic-Subgoal Diffused Policy Learning | Yaocheng Zhang, Yuanheng Zhu, Yuqian Fu, Songjun Tu, Dongbin Zha |
| 803 | Improving Policy Optimization via 𝜺-Retrain | Luca Marzari, Priya L. Donti, Changliu Liu, Enrico Marchesini |
| 507 | Making Universal Policies Universal | Niklas Hoepner, David Kuric, Herke van Hoof |
| 842 | Experience-replay Innovative Dynamics | Tuo Zhang, Leonardo Stella, Julian Barreiro-Gomez |
| 890 | Improving the effectiveness of potential-based reward shaping in reinforcement learning | Henrik Müller, Daniel Kudenko |
| 863 | CPE: A New Paradigm for Policy Extraction in Offline Reinforcement Learning | Zhaohui Yang, Xiaoxuan Wang, Linjing Li |
| 1002 | Action-Dependent Optimality-Preserving Reward Shaping | Grant Collier Forbes, Jianxun Wang, Leonardo Villalobos-Arias, Arnav Jhala, David Roberts |
SIM (13)
| ID | Title | Authors |
|---|---|---|
| 1250 | ShipNaviSim: Data-Driven Simulation for Real-World Maritime Navigation | Quang Anh Pham, Janaka Chathuranga Brahmanage, Akshat Kumar |
| 1009 | Agent-based Modeling and Simulation of Ambiguity in Catastrophe Insurance Markets | YU BI, Lingxiao Zhao, Jinyun Tong, Zhe Feng, Carmine Ventre |
| 457 | Artificial Agents Mitigate The Punishment Dilemma Of Indirect Reciprocity | Alexandre S. Pires, Fernando P. Santos |
| 297 | Simulating and Evaluating Generative Modeling and Collaborative Filtering in Complex Social Networks | Wen Dong, Fairul Mohd-Zaid |
| 119 | On the limits of agency in agent-based models | Ayush Chopra, Shashank Kumar, Nurullah Giray Kuru, Ramesh Raskar, Arnau Quera-Bofarull |
| 900 | Agent-Based Analysis of Green Disclosure Policies and Their Market-Wide Impact on Firm Behavior | Lingxiao Zhao, Maria Polukarov, Carmine Ventre |
| 160 | EconoJax: A Fast & Scalable Economic Simulation in JAX | Koen Ponse, Aske Plaat, Niki van Stein, Thomas M. Moerland |
| 155 | Transformer Guided Coevolution: Improved Team Formation in Multiagent Adversarial Games | Pranav Rajbhandari, Prithviraj Dasgupta, Donald Sofg |
| 173 | Shifting Power: Leveraging LLMs to Simulate Human Aversion in ABMs of Bilateral Financial Exchanges, A bond market study. | Alicia Vidler, Toby Walsh |
| 181 | Multi-Agent Systems for Bullying Intervention | Luis Zhinin-Vera, José J González-García, Víctor López-Jaquero, Elena Navarro, Pascual González |
| 1216 | EconTwo: A Two-Level Multi-Agent Framework for Dynamic Macroeconomic Modeling with Shock Resilience | Zhixun Chen, Zijing Shi, Yaodong Yang, Meng Fang, Yali Du |
| 1348 | Coordinating Competing Electric Vehicle Fleets: An Agent-Based Charging Capacity Market | Lennard Sund, Janik Muires, Ramin Ahadi, Konstantina Valogianni, Wolfgang Ketter |
| 102 | ADAGE: A generic two-layer framework for adaptive agent based modelling | Benjamin Patrick Evans, Sihan Zeng, Sumitra Ganesh, Leo Ardon |
SOPS/RPR (19)
| ID | Title | Authors |
|---|---|---|
| 244 | MAGNET: A Multi-Agent Graph Neural Network for Efficient Bipartite Task Assignment | Donald Loveland, James Usevitch, Zachary Serlin, Danai Koutra, Rajmonda S. Caceres |
| 284 | Approximation Algorithms for Connected Maximum Coverage | Gianlorenzo D’Angelo, Esmaeil Delfaraz |
| 1283 | Emit As You Go: Enumerating Edges of a Spanning Tree | Katrin Casel, Stefan Neubert |
| 1008 | Extending Consensus-based Task Allocation Algorithms with Bid Intercession to Foster Mixed-Initiative | Victor Guillet, Charles Lesire, Gauthier Picard, Christophe Grand |
| 1233 | Reinforcement Learning Based Simulated Annealing | Nathan Qiu, Daniel Dali Liang |
| 265 | Algorithmically Fair Maximization of Multiple Submodular Objective Functions | Georgios Amanatidis, Georgios Birmpas, Philip Lazos, Stefano Leonardi, Rebecca Reiffenhäuser |
| 564 | Maximizing Truth Learning in a Social Network is NP-hard | Filip Úradník, Amanda Wang, Jie Gao |
| 1317 | Ready, Bid, Go! On-Demand Delivery Using Fleets of Drones with Unknown Heterogeneous Energy Storage Constraints | Mohamed S. Talamali, Genki Miyauchi, Thomas Watteyne, Micael Santos Couceiro, Roderich Gross |
| 1289 | Optimising expectation with guarantees for window mean payoff in Markov decision processes | Pranshu Gaba, Shibashis Guha |
| 795 | Decentralized Planning Using Probabilistic Hyperproperties | Francesco Pontiggia, Filip Macák, Roman Andriushchenko, Michele Chiari, Milan Ceska |
| 162 | Tighter Value-Function Approximations for POMDPs | Merlijn Krale, Wietze Koops, Sebastian Junges, Thiago D. Simão, Nils Jansen |
| 1113 | Multi-Objective Planning with Contextual Lexicographic Reward Preferences | Pulkit Rustagi, Yashwanthi Anand, Sandhya Saisubramanian |
| 908 | Conditional Max-Sum for Asynchronous Multiagent Decision Making | Dimitrios Troullinos, Georgios Chalkiadakis, Ioannis Papamichail, Markos Papageorgiou |
| 714 | Single-Agent Planning in a Multi-Agent System: A Unified Framework for Type-Based Planners | Fengming ZHU, Fangzhen Lin |
| 1392 | Minimizing Makespan with Conflict-Based Search for Optimal Multi-Agent Path Finding | Amir Maliah, Dor Atzmon, Ariel Felner |
| 424 | Insights Regarding the Success of Damping in Improving Belief Propagation | Uriel Zaed, Roie Zivan, Omer Lev |
| 590 | AlphaZeroES: Direct Score Maximization Outperforms Planning Loss Minimization | Carlos Martin, Tuomas Sandholm |
| 175 | Observer-Aware Probabilistic Planning under Partial Observability | Salomé Lepers, Vincent Thomas, Olivier Buffet |
| 877 | Where is the nearest EV charging station? Evolutionary optimization of the gas/charging stations topology | Enrique Mateos-Melero, Javier Moralejo-Piñas, Ángela Durán-Pinto, Francisco Martinez-Gil, María Soriano, Fernando Fernández |
Poster Session 2 (PS2): May 21 Afternoon
Date & Time: Wednesday, May 21, 3:45PM – 4:30PM
Total number of posters: 57
GTEP (24)
| ID | Title | Authors |
|---|---|---|
| 398 | Incentives for Early Arrival in Cost Sharing | Junyu Zhang, Yao Zhang, Yaoxin Ge, Dengji Zhao, Hu Fu, Zhihao Gavin Tang, Pinyan Lu |
| 905 | An Improved Mechanism for Pricing Ride-Hailing Fares | Marek Adamczyk, Maurycy Borkowski, Michał Pawłowski |
| 129 | FLIGHT: Facility Location Integrating Generalized, Holistic Theory of Welfare | Avyukta Manjunatha Vummintala, Shivam Gupta, Shweta Jain, Sujit Gujar |
| 165 | Incentivizing Truth Exploration and Honest Reporting: A Contract Design Approach | Yuming Shao, Zhixuan Fang |
| 434 | Truthful mechanisms for linear bandit games with private contexts | Yiting Hu, Lingjie Duan |
| 393 | Truthful and Welfare-maximizing Resource Scheduling with Application to Electric Vehicles | Ramsundar Anandanarayanan, Swaprava Nath, Prasant Misra |
| 845 | Ranking Joint Policies in Dynamic Games using Evolutionary Dynamics | Natalia Koliou, George Vouros |
| 813 | Temporal Network Creation Games: The Impact of Non-Locality and Terminals | Davide Bilò, Sarel Cohen, Tobias Friedrich, Hans Gawendowicz, Nicolas Klodt, Pascal Lenzner, George Skretas |
| 513 | Non-obvious Manipulability in Hedonic Games with Friends Appreciation Preferences | Michele Flammini, Maria Fomenko, Giovanna Varricchio |
| 334 | Welfare Approximation in Additively Separable Hedonic Games | Martin Bullinger, Vaggos Chatziafratis, Parnian Shahkar |
| 1293 | Maximizing Value in Challenge the Champ Tournaments | Umang Bhaskar, Juhi Chaudhary, Palash Dey |
| 1393 | Towards Envy-Freeness Relaxations for General Nonmonotone Valuations | Umang Bhaskar, Gunjan Kumar, Yeshwant Pandit, Rakshitha |
| 1394 | On the Structure of EFX Orientations on Graphs | Jinghan Zeng, Ruta Mehta |
| 274 | Learning Fair and Preferable Allocations through Neural Network | Ryota Maruo, Koh Takeuchi, Hisashi Kashima |
| 972 | Participatory Budgeting Project Strength via Candidate Control | Piotr Faliszewski, Łukasz Janeczko, Dušan Knop, Jan Pokorný, Šimon Schierreich, Mateusz Słuszniak, Krzysztof Sornat |
| 1263 | On the existence of EFX allocations in multigraphs | Alkmini Sgouritsa, Minas Marios Sotiriou |
| 1366 | Adaptive Microtolling in Competitive Online Congestion Games via Multiagent Reinforcement Learning | Behrad Koohy, Sebastian Stein, Enrico Gerding |
| 205 | Voter Participation Control in Online Polls | Koustav De, Palash Dey, Swagato Sanyal |
| 133 | Shapley Value-based Approach for Distributing Revenue of Matchmaking of Private Transactions in Blockchains | Rasheed, Parth Desai, Yash Chaurasia, Sujit Gujar |
| 993 | (Submodular) Hedonic Games with Common Ranking Property | Bugra Caskurlu, Ali Eser |
| 1237 | Group-fair Facility Location Games with Externalities | Minming Li, Cheng Peng, Ying Wang, Houyu Zhou |
| 951 | When to Stop Getting Tested: The Theory of Diagnostic Tests | Anson Kahng, Joseph Saber |
| 991 | Diversity-seeking swap games in networks | Yaqiao Li, Lata Narayanan, Jaroslav Opatrny |
| 380 | Learning Bayesian Game Families, with Application to Mechanism Design | Madelyn Gatchel, Michael P. Wellman |
LEARN (23)
| ID | Title | Authors |
|---|---|---|
| 550 | Ensemble Value Functions for Efficient Exploration in Multi-Agent Reinforcement Learning | Lukas Schäfer, Oliver Slumbers, Stephen Marcus McAleer, Yali Du, Stefano V Albrecht, David Henry Mguni |
| 605 | An Organizationally-Oriented Approach to Enhancing Explainability and Control in Multi-Agent Reinforcement Learning | Julien Soulé, Jean-Paul Jamont, Michel Occello, Louis-Marie Traonouez, Paul Théron |
| 646 | Loss of Plasticity: A New Perspective on Solving Multi-Agent Exploration for Sparse Reward Tasks | Zehua Zang, Chuxiong Sun, Lixiang Liu, Fuchun Sun, Changwen Zheng |
| 533 | Dynamic Sight Range Selection in Multi-Agent Reinforcement Learning | Wei-Chen Liao, Ti-Rong Wu, I-Chen Wu |
| 628 | Revisiting Communication Efficiency in Multi-Agent Reinforcement Learning from the Dimensional Analysis Perspective | Chuxiong Sun, Peng He, Rui Wang, Changwen Zheng |
| 526 | Unveiling Decision Intention for Cooperative Multi-Agent Reinforcement Learning | Zeren Zhang, Zhiwei Xu, Guangchong Zhou, Dapeng Li, Bin Zhang, Guoliang Fan |
| 756 | An Extended Benchmarking of Multi-Agent Reinforcement Learning Algorithms in Complex Fully Cooperative Tasks | George Papadopoulos, Andreas Kontogiannis, Foteini Papadopoulou, Chaido Poulianou, Ioannis Koumentis, George Vouros |
| 762 | Mitigating Value Conflicts with Computational Theory of Mind | Emre Erdogan, Hüseyin Aydın, Frank Dignum, Rineke Verbrugge, Pinar Yolum |
| 67 | Online Preference-based Reinforcement Learning with Self-augmented Feedback from Large Language Model | Songjun Tu, Jingbo Sun, Qichao Zhang, Xiangyuan Lan, Dongbin Zhao |
| 1005 | HAVA: Hybrid Approach to Value-Alignment through Reward Weighing for Reinforcement Learning | Kryspin Varys, Federico Cerutti, Adam Sobey, Timothy J. Norman |
| 709 | FedRLHF: A Convergence-Guaranteed Federated Framework for Privacy-Preserving and Personalized RLHF | Flint Xiaofeng Fan, Cheston Tan, Yew-Soon Ong, Roger Wattenhofer, Wei Tsang Ooi |
| 667 | Human-Aligned Skill Discovery: Balancing Behaviour Exploration and Alignment | Maxence Hussonnois, Thommen George Karimpanal, Santu Rana |
| 167 | Personality-Driven Decision Making in LLM-Based Autonomous Agents | Lewis Newsham, Daniel Prince |
| 1141 | Learning Flexible Heterogeneous Coordination With Capability-Aware Shared Hypernetworks | Kevin Fu, Pierce Howell, Shalin Jain, Harish Ravichandar |
| 1194 | Asynchronous Cooperative Multi-Agent Reinforcement Learning with Limited Communication | Sydney Dolan, Siddharth Nayak, Jasmine Jerry Aloor, Hamsa Balakrishnan |
| 520 | Boosting Robustness in Preference-Based Reinforcement Learning with Dynamic Sparsity | Calarina Muslimani, Bram Grooten, Deepak Ranganatha Sastry Mamillapalli, Mykola Pechenizkiy, Decebal Constantin Mocanu, Matthew E. Taylor |
| 223 | Fast Adaption by Policy Deviation Integral Meta-reinforcement Learning with Applications to High-speed Trains Operation | Haotong Zhang, Wanyuan Wang |
| 444 | Distributed Value Decomposition Networks with Networked Agents | Guilherme S. Varela, Alberto Sardinha, Francisco S. Melo |
| 278 | Towards Automating the Design of Value-Aligned Clinical Protocols | Manel Rodriguez-Soto, Nardine Osman, Carles Sierra, Rocio Cintas-Garcia, Cristina Farriols-Danes, Montserrat Garcia-Retortillo, Silvia Minguez-Maso, Jordi Martinez-Roldan |
| 275 | Multi-Objective Reinforcement Learning for Water Management | Zuzanna Osika, Roxana Rădulescu, Jazmin Zatarain Salazar, Frans A Oliehoek, Pradeep K. Murukannaiah |
| 88 | Empowering Generalization for Deep Reinforcement Learning via Symbolic Planning | Tianpei Yang, Srijita Das, Christabel Wayllace, Matthew E. Taylor |
| 222 | Leveraging Fully-Observable Solutions for Improved Partially-Observable Offline Reinforcement Learning | Chulabhaya Wijesundara, Andrea Baisero, Gregory David Castanon, Alan Carlin, Robert Platt, Christopher Amato |
| 1010 | Finite-Horizon Single-Pull Restless Bandits: An Efficient Index Policy For Scarce Resource Allocation | Guojun Xiong, Haichuan Wang, Yuqi Pan, Saptarshi Mandal, Sanket Shah, Niclas Boehmer, Milind Tambe |
SOPS/RPR (10)
| ID | Title | Authors |
|---|---|---|
| 518 | Alternating-time Temporal Logic with Stochastic Abilities | Gabriel Ballot, Vadim Malvone, Jean Leneutre, Jingxuan Ma, Mourad Leslous |
| 874 | Formalising Overdetermination in a Labelled Transition System | Gauvain Bourgne, Camilo Sarmiento, Jean Gabriel Gustave Ganascia |
| 977 | LTL Verification of Memoryful Neural Agents | Mehran Hosseini, Alessio Lomuscio, Nicola Paoletti |
| 968 | Certified Guidance for Planning with Deep Generative Models | Francesco Giacomarra, Mehran Hosseini, Nicola Paoletti, Francesca Cairoli |
| 14 | Automatic Verification of Linear Integer Planning Programs via Forgetting in LIAUPF | Liangda Fang, Shikang Chen, Xiaoman Wang, Xiaoyou Lin, Chenyi Zhang, Qingliang Chen, Quanlong Guan, Kaile Su |
| 909 | Probabilistic Timed ATL | Wojciech Jamroga, Marta Kwiatkowska, Wojciech Penczek, Laure Petrucci, Teofil Sidoruk |
| 1036 | xSRL: Safety-Aware Explainable RL – Safety as a Product of Explainability | Risal Shahriar Shefin, Md Asifur Rahman, Thai Le, Sarra Alqahtani |
| 1204 | Resolving Multiple-Dynamic Model Uncertainty in Hypothesis-Driven Belief-MDPs | Ofer Dagan, Tyler Becker, Zachary N Sunberg |
| 426 | Adaptive Budget Optimization for Multichannel Advertising Using Combinatorial Bandits | Briti Gangopadhyay, Zhao Wang, Alberto Silvio Chiappa, Shingo Takamatsu |
| 1018 | Planning for Temporally Extended Goals based on alpha-CTL | Viviane Bonadia dos Santos, Leliane N. de Barros, Maria Viviane de Menezes, Silvio do Lago Pereira |
Poster Session 3 (PS3): May 22 Morning
Date & Time: Thursday, May 22, 10:00AM – 10:45AM
Total number of posters: 66
GTEP (18)
| ID | Title | Authors |
|---|---|---|
| 797 | Games in Public Announcement: How to Reduce System Losses in Optimistic Blockchain Mechanisms | Siyuan Liu, Yulong Zeng |
| 224 | Factorised Active Inference for Strategic Multi-Agent Interactions | Jaime Ruiz-Serra, Patrick Sweeney, Michael Harre |
| 511 | Simplifying imperfect recall games | Hugo Gimbert, Soumyajit Paul, B. Srivathsan |
| 587 | ApproxED: Approximate Exploitability Descent via Learned Best Responses | Carlos Martin, Tuomas Sandholm |
| 730 | Equilibrium Analysis in Markets with Asymmetric Utility Functions | Martin Bichler, Markus Ewert, Axel Ockenfels |
| 917 | Policy Abstraction and Nash Refinement in Tree-Exploiting PSRO | Christine Konicki, Mithun Chakraborty, Michael P. Wellman |
| 282 | Robin Hood Reachability Bidding Games | Shaull Almagor, Guy Avni, Neta Dafni |
| 1209 | The Degree of (Extended) Justified Representation and Its Optimization | Biaoshuai Tao, Chengkai Zhang, Houyu Zhou |
| 1226 | Full Proportional Justified Representation | Yusuf Hakan Kalayci, Jiasen Liu, David Kempe |
| 933 | Selecting Interlacing Committees | Chris Dong, Martin Bullinger, Tomasz Wąs, Larry Birnbaum, Edith Elkind |
| 154 | Boosting Sortition via Proportional Representation | Soroush Ebadian, Evi Micha |
| 1142 | Who Reviews The Reviewers? A Multi-Level Jury Problem | Ben Abramowitz, Omer Lev, Nicholas Mattei |
| 1064 | The Price of Anarchy in Spatial Social Choice | James Patrick Bailey, Craig Tovey |
| 790 | Learning Real-Life Approval Elections | Piotr Faliszewski, Łukasz Janeczko, Andrzej Kaczmarczyk, Marcin Kurdziel, Grzegorz Pierczyński, Stanisław Szufa |
| 614 | Approximation Ratio for Preference Aggregation Using Tree CP-Nets | Abu Mohammad Hammad Ali, Daniel Ogundare, Boting Yang, Sandra Zilles |
| 429 | Parameterized Complexity of Hedonic Games with Enemy-Oriented Preferences | Martin Durand, Laurin Erlacher, Johanne Müller Vistisen, Sofia Simola |
| 975 | Bridging the Gap between Partially Observable Stochastic Games and Sparse POMDP Methods | Tyler Becker, Zachary N Sunberg |
| 1335 | To Stand on the Shoulders of Giants: Should We Protect Initial Discoveries in Multi-Agent Exploration? | Hodaya Lampert, Reshef Meir, Kinneret Teodorescu |
LEARN (14)
| ID | Title | Authors |
|---|---|---|
| 302 | Divide and Conquer: Provably Unveiling the Pareto Front with Multi-Objective Reinforcement Learning | Willem Röpke, Mathieu Reymond, Patrick Mannion, Diederik M Roijers, Ann Nowe, Roxana Rădulescu |
| 946 | Multi-objective Reinforcement Learning with Nonlinear Preferences: Provable Approximation for Maximizing Expected Scalarized Return | Nianli Peng, Muhang Tian, Brandon Fain |
| 950 | Automating Curriculum Learning for Reinforcement Learning using a Skill-Based Bayesian Network | Vincent Hsiao, Mark Roberts, Laura M. Hiatt, George Konidaris, Dana S. Nau |
| 277 | FORM: Learning Expressive and Transferable First-Order Logic Reward Machines | Leo Ardon, Daniel Furelos-Blanco, Roko Parać, Alessandra Russo |
| 357 | Learning Symbolic Task Decompositions for Multi-Agent Teams | Ameesh Shah, Niklas Lauffer, Thomas Chen, Nikhil Pitta, Sanjit A. Seshia |
| 1388 | Evaluation-Time Policy Switching for Offline Reinforcement Learning | Natinael Solomon Neggatu, Jeremie Houssineau, Giovanni Montana |
| 609 | Combining Planning and Reinforcement Learning for Solving Relational Multiagent Domains | Nikhilesh Prabhakar, Ranveer Singh, Harsha Kokel, Sriraam Natarajan, Prasad Tadepalli |
| 111 | AdaCred: Adaptive Causal Decision Transformers with Feature Crediting | Hemant Kumawat, Saibal Mukhopadhyay |
| 656 | Navigating Social Dilemmas with LLM-based Agents via Consideration of Future Consequences | Dung Nguyen, Hung Le, Kien Do, Sunil Gupta, Svetha Venkatesh, Truyen Tran |
| 463 | CDSA: Conservative Denoising Score-based Algorithm for Offline Reinforcement Learning | Zeyuan Liu, Yang Kai, Jiafei Lyu, Xiu Li |
| 26 | Offline Meta Reinforcement Learning with Weighted Policy Constraints and Proximal Context Collection | Haorui Li, Jiaqi Liang, Linjing Li, Daniel Dajun Zeng |
| 296 | Adaptive Offline Data Replay in Offline-to-Online Reinforcement Learning | Xu Liu, Tong Yu, Shuai Li |
| 1053 | Tools in the Loop: Quantifying Uncertainty of LLM Question Answering Systems That Use Tools | Panagiotis Lymperopoulos, Vasanth Sarathy |
| 350 | On-Policy Reinforcement Learning From Failure via Sparse Reward Densification | Mingkang Wu, Yongcan Cao |
SOPS/RPR (13)
| ID | Title | Authors |
|---|---|---|
| 427 | Translating Multi-Agent Modal Logics of Knowledge and Belief into Decidable First-Order Fragments | Qihui Feng, Hannah Wilk, Shakil M Khan, Gerhard Lakemeyer |
| 37 | Impact Measures for Gradual Argumentation Semantics | Caren Al Anaissy, Jérôme Delobelle, Srdjan Vesic, Bruno Yun |
| 999 | Policy Graphs and Intention: answering ’why’ and ’how’ from a telic perspective | Victor Gimenez-Abalos, Sergio Alvarez-Napagao, Adrián Tormos, Ulises Cortés, Javier Vazquez-Salceda |
| 1273 | On Learning Informative Trajectory Embeddings for Imitation, Classification, and Regression | Zichang Ge, Changyu Chen, Arunesh Sinha, Pradeep Varakantham |
| 865 | Greedy ABA Learning for Case-Based Reasoning | Emanuele De Angelis, Maurizio Proietti, Francesca Toni |
| 4 | Logic of Knowledge and Cognitive Ability | Jia Tao, Xinran Zhang |
| 887 | A Simple Integration of Epistemic Logic and Reinforcement Learning | Thorsten Engesser, Thibaut Le Marre, Emiliano Lorini, François Schwarzentruber, Bruno Zanuttini |
| 170 | Learning Graph Representation of Agent Diffusers | Youcef Djenouri, Nassim Belmecheri, Tomasz Pawel Michalak, Jan Dubiński, Ahmed Nabil Belbachir, Anis Yazidi |
| 172 | Robust Strategies for Stochastic Multi-Agent Systems | Raphaël Berthon, Joost-Pieter Katoen, Munyque Mittelmann, Aniello Murano |
| 735 | Multiplayer Games With Incomplete Information for Hyperproperty Verification | Raven Beutner, Bernd Finkbeiner |
| 449 | Managing an Agent’s Changing Intentions Using LTL𝑓 Synthesis | Giuseppe De Giacomo, Yves Lesperance, Gianmarco Parretti, Fabio Patrizi, Renzo Schram |
| 758 | What Is a Counterfactual Cause in Action Theories? | Daxin Liu, Vaishak Belle |
| 1040 | Formal Verification of Manipulation Dialogues | Andreas Brännström, Chiaki Sakama, Juan Carlos Nieves |
COINE (21)
| ID | Title | Authors |
|---|---|---|
| 1307 | Preventing Misinformation with Redundancy in Emergent Communication | Fábio Vital, Alberto Sardinha, Francisco S. Melo |
| 942 | Emergence of Recursive Language through Bootstrapping and Iterated Learning | Vikas Kumar, Ajin George Joseph |
| 932 | Coherence-Driven Multimodal Safety Dialogue with Active Learning for Embodied Agents | Sabit Hassan, Hye-Young Chung, Xiang Zhi Tan, Malihe Alikhani |
| 630 | TACTIC: Task-Agnostic Contrastive pre-Training for Inter-Agent Communication | Peihong Yu, Manav Mishra, Syed Zaidi, Pratap Tokekar |
| 592 | SCMRAG: Self-Corrective Multihop Retrieval Augmented Generation System for LLM Agents | Rishabh Agrawal, Murtaza Asrani, Hadi Youssef, Apurva Narayan |
| 1103 | Dynamic Coalition Structure Detection in Natural-Language-based Interactions | Abhishek Ninad Kulkarni, Andy Liu, Jean-Raphaël Gaglione, Daniel Fried, ufuk topcu |
| 303 | Curiosity-Driven Partner Selection Accelerates Convention Emergence in Language Games | Chin-wing Leung, Paolo Turrini, Ann Nowe |
| 1189 | Counterfactual Explanations for Model Ensembles Using Entropic Risk Measures | Erfaun Noorani, Pasan Dissanayake, Faisal Hamman, Sanghamitra Dutta |
| 621 | Who Am I Dealing With? Explaining the Designer’s Hidden Intentions | Turgay Caglar, Sarath Sreedharan, Mor Vered |
| 1020 | Feature Engineering for Agents: An Adaptive Cognitive Architecture for Interpretable ML Monitoring | Gusseppe Bravo-Rocca, Peini Liu, Jordi Guitart, Rodrigo M Carrillo-Larco, Ajay Dholakia, David Ellison |
| 367 | A Scoresheet for Explainable AI | Michael Winikoff, John Thangarajah, Sebastian Rodriguez |
| 765 | Free Argumentative Exchanges for Explaining Image Classifiers | Avinash Kori, Antonio Rago, Francesca Toni |
| 699 | Explaining Facial Expression Recognition | Sanjeev Nahulanthran, Leimin Tian, Dana Kulic, Mor Vered |
| 1387 | Contrastive Explainable Clustering with Differential Privacy | Ariel Vetzler, Dung Nguyen, Sarit Kraus, Anil Vullikanti |
| 944 | Neural DNF-MT: A Neuro-symbolic Approach for Learning Interpretable and Editable Policies | Kexin Gu Baugh, Luke Dickens, Alessandra Russo |
| 1308 | Will Systems of LLM Agents Lead to Cooperation: An Investigation into a Social Dilemma | Richard Willis, Yali Du, Joel Z Leibo |
| 952 | Cultural Evolution of Cooperation among LLM Agents | Aron Vallinder, Edward Hughes |
| 626 | Rethinking Explainable AI: Explanations can be Deceiving | Peta Masters, Daniel Gallagher, Luc Moreau, Mor Vered |
| 541 | ChatBDI: Think BDI, Talk LLM | Andrea Gatti, Viviana Mascardi, Angelo Ferrando |
| 768 | Quantitative Operational Monitoring for BDI Agents | Marie Farrell, Angelo Ferrando, Mengwei Xu |
| 876 | Agreement Games in Multi-Agent Systems | Davide Catta, Angelo Ferrando, Vadim Malvone |
Poster Session 4 (PS4): May 22 Afternoon
Date & Time: Thursday, May 22, 3:45PM – 4:30PM
Total number of posters: 59
GTEP (26)
| ID | Title | Authors |
|---|---|---|
| 696 | Housing Market on Networks | Xinwei Song, Tianyi Yang, Dengji Zhao |
| 27 | The Strong Core of Housing Markets with Partial Order Preferences | Ildikó Schlotter, Lydia Mirabel Mendoza-Cadena |
| 73 | To Spend or to Gain: Online Learning in Repeated Karma Auctions | Damien Berriaud, Ezzat Elokda, Devansh Jalota, Emilio Frazzoli, Marco Pavone, Florian Dorfler |
| 1102 | Indifferential Privacy: A New Paradigm and Its Applications to Optimal Matching in Dark Pool Auctions | Antigoni Polychroniadou, T-H. Hubert Chan, Adya Agrawal |
| 462 | Opinion Dynamics with Median Aggregation | Petra Berenbrink, Martin Hoefer, Dominik Kaaser, Marten Maack, Malin Rau, Lisa Wilhelmi |
| 1188 | Learning Collusion in Episodic, Inventory-Constrained Markets | Paul Friedrich, Barna Pásztor, Giorgia Ramponi |
| 683 | Data Pricing for Graph Neural Networks without Pre-purchased Inspection | Yiping Liu, Mengxiao Zhang, Jiamou Liu, Song Yang |
| 1303 | DUPRE: Data Utility Prediction for Efficient Data Valuation | Pham Kieu Thao Nguyen, Rachael Hwee Ling Sim, Quoc Phong Nguyen, See-Kiong Ng, Bryan Kian Hsiang Low |
| 335 | Fairly Allocating Goods in Parallel | Rohan Garg, Alexandros Psomas |
| 671 | Fair Allocation of Divisible Goods under Non-Linear Valuations | Haris Aziz, Zixu He, Xinhang Lu, Kaiyang Zhou |
| 495 | On the Hardness of Fair Allocation under Ternary Valuations | Zack Fitzsimmons, Vignesh Viswanathan, Yair Zick |
| 146 | On the Fairness of Additive Welfarist Rules | Karen Frilya Celine, Warut Suksompong, Sheung Man Yuen |
| 664 | EFX Allocations and Orientations on Bipartite Multi-graphs: A Complete Picture | Mahyar Afshinmehr, Alireza Danaei, Mehrafarin Kazemi, Kurt Mehlhorn, Nidhi Rathi |
| 330 | Computing Efficient Envy-Free Partial Allocations of Indivisible Goods | Robert Bredereck, Andrzej Kaczmarczyk, Junjie Luo, Bin Sun |
| 472 | Fair Division in a Variable Setting | Harish Chandramouleeswaran, Prajakta Nimbhorkar, Nidhi Rathi |
| 523 | Temporal Fair Division of Indivisible Items | Edith Elkind, Alexander Lam, Mohamad Latifian, Tzeh Yuan Neoh, Nicholas Teh |
| 1155 | Liquid Welfare and Revenue Monotonicity in Adaptive Clinching Auctions | Ryosuke Sato |
| 1021 | Efficient Multi-Agent Delegated Search | Curtis Bechtel, Shaddin Dughmi |
| 682 | Satisfactory Budget Division | Laurent Gourvès, Michael Lampis, Nikolaos Melissinos, Aris Pagourtzis |
| 970 | Weighted Envy Freeness With Bounded Subsidies | Noga Klein Elmalem, Rica Gonen, Erel Segal-Halevi |
| 1138 | Weighted Envy-free Allocation with Subsidy | Haris Aziz, Xin Huang, Kei Kimura, Indrajit Saha, Zhaohong Sun, Mashbat Suzuki, Makoto Yokoo |
| 123 | Group Fairness in Multi-period Mobile Facility Location Problems | Haris Aziz, Hau Chan, Xingchen Sha, Toby Walsh, Lirong Xia |
| 396 | Optimal Mechanism Design for Crowdfunding of Public Goods | Yukun Cheng, Xiaotie Deng, Baqiao Quan |
| 723 | Environmental Policies within Cournot Oligopoly | Liang Shan, Zhengyang Liu, Haoqiang Huang, Zihe Wang |
| 190 | Fair Assignment on Multi-Stage Graphs | Vibulan J, Swapnil Dhamal, Shweta Jain, Ojassvi Kumar, Aman Kumar, Harpreet Singh |
| 962 | Adaptive Multi-Round Influence Maximization with Limited Information | Diodato Ferraioli, Vincenzo Auletta, Cosimo Vinci, Francesco Carbone |
LEARN (13)
| ID | Title | Authors |
|---|---|---|
| 787 | PMAT: Optimizing Action Generation Order in Multi-Agent Reinforcement Learning | Kun Hu, Muning Wen, Xihuai Wang, Shao Zhang, Yiwei Shi, Minne Li, Minglong Li, Ying Wen |
| 930 | Taming Multi-Agent Reinforcement Learning with Estimator Variance Reduction | Taher Jafferjee, Juliusz Ziomek, Tianpei Yang, Zipeng Dai, Jianhong Wang, Matthew E. Taylor, Kun Shao, Jun Wang, David Henry Mguni |
| 389 | Offline-to-Online Multi-Agent Reinforcement Learning with Offline Value Function Memory and Sequential Exploration | Hai Zhong, Xun Wang, Zhuoran Li, Longbo Huang |
| 805 | On Stateful Value Factorization in Multi-Agent Reinforcement Learning | Enrico Marchesini, Andrea Baisero, Rupali Bhati, Christopher Amato |
| 159 | Dual Ensembled Multiagent Q-Learning with Hypernet Regularizer | Yaodong Yang, Guangyong Chen, Hongyao Tang, Furui Liu, Danruo Deng, Pheng-Ann Heng |
| 116 | Adaptive Episode Length Adjustment for Multi-agent Reinforcement Learning | Byunghyun Yoo, Younghwan Shin, Hyunwoo Kim, Euisok Chung, Jeongmin Yang |
| 1140 | Leveraging Large Language Models for Effective and Explainable Multi-Agent Credit Assignment | Kartik Nagpal, Dayi Ethan Dong, Negar Mehr |
| 941 | EnEnv 1.0: Energy Grid Environment for Multi-Agent Reinforcement Learning Benchmarking | Dominik Jacek Bogucki, Łukasz Eugeniusz Lepak, Sonam Parashar, Bart Blachowski, Paweł Wawrzyński |
| 860 | Entropic Exploration for Constrained Multiagent Reinforcement Learning | Ayhan Alp Aydeniz, Enrico Marchesini, Robert Loftin, Christopher Amato, Kagan Tumer |
| 689 | Decentralized Deep Reinforcement Learning for Cooperative Multi-Agent Flight Trajectory Planning in Adverse Weather | Bizhao Pang, Mingcheng Zhang, Xinting Hu, sameer alam, Guglielmo Lulli |
| 260 | Dynamic Conservative Degree Allocation for Offline Multi-Agent Reinforcement Learning | Haosheng Chen, Yun Hua, Junjie Sheng, Wenhao Li, Bo Jin, Xiangfeng Wang |
| 584 | Hierarchical Multi-agent Reinforcement Learning for Cyber Network Defense | Aditya Vikram Singh, Ethan Rathbun, Emma Graham, Lisa Oakley, Simona Boboila, Alina Oprea, Peter Chin |
| 1025 | Fairness in Cooperative Multiagent Multiobjective Reinforcement Learning using the Expected Scalarized Reward Criterion | Fares Chouaki, Aurélie Beynier, Nicolas Maudet, Paolo Viappiani |
SOPS/RPR (8)
| ID | Title | Authors |
|---|---|---|
| 1176 | Hitchhiker’s Guide to Patrolling: Path-Finding for Energy-Sharing Drone-UGV Teams | Jonathan Diller, Qi Han, Robert Byers, James Dotterweich, James Humann |
| 1389 | CAMP: Collaborative Attention Model with Profiles for Vehicle Routing Problems | Chuanbo Hua, Federico Berto, Jiwoo Son, Seunghyun Kang, Changhyun Kwon, Jinkyoo Park |
| 1346 | Parameterized Algorithms for Multiagent Pathfinding on Trees | Argyrios Deligkas, Eduard Eiben, Robert Ganian, Iyad A. Kanj, Ramanujan Sridharan |
| 91 | On the Power of Temporal Locality on Online Routing Problems | Swapnil Guragain, Gokarna Sharma |
| 337 | Towards Fair and Efficient Public Transportation: A Bus Stop Model | Martin Bullinger, Edith Elkind, Mohamad Latifian |
| 448 | Interaction Protocols in an Imperative Agent-Oriented Programming Language: the case of BSPL and SARL | Matteo Baldoni, Cristina Baroglio, Stéphane Galland, Roberto Micalizio, Fatma Outay, Stefano Tedeschi |
| 348 | Enhancing Lifelong Multi-Agent Path-finding by Using Artificial Potential Fields | Arseniy Pertzovsky, Roni Stern, Roie Zivan, Ariel Felner |
| 1073 | Online Competitive Information Gathering for Partially Observable Trajectory Games | Mel Krusniak, Hang Xu, Parker Palermo, Forrest John Laine |
HAI/XAI (12)
| ID | Title | Authors |
|---|---|---|
| 1381 | Modeling the Centaur: Human-Machine Synergy in Sequential Decision Making | David Shoresh, Yonatan Loewenstein |
| 571 | Socratic: Enhancing Human Teamwork via AI-enabled Coaching | Sangwon Seo, Bing Han, Rayan Ebnali Harari, Roger Daglius Dias, Marco A. Zenati, Eduardo Salas, Vaibhav V. Unhelkar |
| 243 | Human-Agent Coordination in Games under Incomplete Information via Multi-Step Intent | Shenghui Chen, Ruihan Zhao, Sandeep P. Chinchali, Ufuk Topcu |
| 1265 | Conformal Set-based Human-AI Complementarity with Multiple Experts | Helbert Paat, Guohao Shen |
| 1026 | Uncertainty Expression for Human-Robot Task Communication | David Porfirio, Mark Roberts, Laura M. Hiatt |
| 1068 | An AI-Driven Card Playing Robot: An Empirical Study on Communicative Style and Embodiment with Elderly Adults | Michael Banck, Elisabeth Ganal, Hanna-Finja Weichert, Frank Puppe, Birgit Lugrin |
| 308 | Investigating the Perspective of Non-Native Speakers on Foreigner-Directed Speech using Virtual Agents: The Role of Racial Ingroup Affiliation and Language Proficiency on Perception and Comprehension | Ohenewa Bediako Akuffo, Birgit Lugrin |
| 897 | Can you see how I learn? Human observers’ inferences about Reinforcement Learning agents’ learning processes | Bernhard Hilpert, Muhan Hou, Kim Baraka, Joost Broekens |
| 109 | Predicting Team Performance from Communications in Simulated Search-and-Rescue | Ali Jalal-Kamali, Nikolos M Gurney, David V. Pynadath |
| 1291 | Decoding Negotiation Dynamics: The Impact of Opponent Identity and Privacy on Strategy, Deception, and Emotional Transparency in Human-Agent Interaction | Nusrath Jahan, Johnathan Mell |
| 525 | Combining LLMs with a Logic-Based Framework to Explain MCTS | Ziyan An, Xia Wang, Hendrik Baier, Zirong Chen, Abhishek Dubey, Taylor T Johnson, Jonathan Sprinkle, Ayan Mukhopadhyay, Meiyi Ma |
| 365 | Requirements-based Explainability for Multi Agent Systems | Sebastian Rodriguez, John Thangarajah, Michael Winikoff |
Poster Session 5 (PS5): May 23 Morning
Date & Time: Friday, May 23, 10:00AM – 10:45AM
Total number of posters: 65
GTEP (8)
| ID | Title | Authors |
|---|---|---|
| 212 | Teamwork Makes the Defense Work: Comprehensive Vulnerability Defense Resource Allocation | Siyu Liu, Rida Bazzi, Fei Fang, Tiffany Bao |
| 45 | Game Theory with Simulation in the Presence of Unpredictable Randomisation | Vojtech Kovarik, Nathaniel Sauerberg, Lewis Hammond, Vincent Conitzer |
| 1377 | Byzantine Game Theory: Sun Tzu’s Boxes | Andrei Constantinescu, Roger Wattenhofer |
| 662 | Global Behavior of Learning Dynamics in Zero-Sum Games with Memory Asymmetry | Yuma Fujimoto, Kaito Ariu, Kenshi Abe |
| 89 | Learning in Games with Progressive Hiding | Benjamin Heymann, Marc Lanctot |
| 1255 | Mean Field Correlated Imitation Learning | Zhiyu Zhao, Chengdong Ma, Qirui Mi, Ning Yang, Xue Yan, Mengyue Yang, Haifeng Zhang, Jun Wang, Yaodong Yang |
| 622 | Scalable Offline Reinforcement Learning for Mean Field Games | Axel Brunnbauer, Julian Lemmel, Zahra Babaiee, Sophie A. Neubauer, Radu Grosu |
| 7 | Nash Equilibrium and Learning Dynamics in Three-Player Matching $m$-Action Games | Yuma Fujimoto, Kaito Ariu, Kenshi Abe |
LEARN (31)
| ID | Title | Authors |
|---|---|---|
| 245 | EduQate: Generating Adaptive Curricula through RMABs in Education Settings | Sidney Tio, Dexun Li, Pradeep Varakantham |
| 391 | Bayesian Collaborative Bandits with Thompson Sampling for Improved Outreach in Maternal Health | Arpan Dasgupta, Gagan Jain, Arun Suggala, Karthikeyan Shanmugam, Milind Tambe, Aparna Taneja |
| 200 | Anytime Fairness Guarantees in Stochastic Combinatorial MABs: A Novel Learning Framework | Subham Pokhriyal, Shweta Jain, Ganesh Ghalme, Vaneet Aggarwal |
| 566 | Efficient and Optimal Policy Gradient Algorithm for Corrupted Multi-armed Bandits | Jiayuan Liu, Siwei Wang, Zhixuan Fang |
| 1304 | Surprise! Surprise! Learn and Adapt | Huma Samin, Dylan J. Walton, Nelly Bencomo |
| 1391 | Composing Reinforcement Learning Policies, with Formal Guarantees | Florent Delgrange, Guy Avni, Anna Lukina, Christian Schilling, Ann Nowe, Guillermo Perez |
| 272 | Real-World Testing Matters in Reinforcement Learning for Education | Anna Riedmann, Carlo D’Eramo, Birgit Lugrin |
| 262 | Imitation from Diverse Behaviors: Wasserstein Quality Diversity Imitation Learning with Single-Step Archive Exploration | Xingrui Yu, Zhenglin Wan, David Mark Bossens, Yueming Lyu, Qing Guo, Ivor Tsang |
| 1049 | Sea-cret Agents: Maritime Abduction for Region Generation to Expose Dark Vessel Trajectories | Divyagna Bavikadi, Nathaniel Lee, Chad Parvis, Paulo Shakarian |
| 819 | Multi-Ship Future Interaction Trajectory Prediction via Pre-Initializer Diffusion Model | Kun Ma, Qilong Han, Jingzheng Yao |
| 778 | GUIDE-CoT: Goal-driven and User-Informed Dynamic Estimation for Pedestrian Trajectory using Chain-of-Thought | Sungsik Kim, Janghyun Baek, Jinkyu Kim, Jaekoo Lee |
| 915 | On Diffusion Models for Multi-Agent Partial Observability: Shared Attractors, Error Bounds, and Composite Flow | Tonghan Wang, Heng Dong, Yanchen Jiang, David C. Parkes, Milind Tambe |
| 729 | Salience-Invariant Consistent Policy Learning for Generalization in Visual Reinforcement Learning | Jingbo Sun, Songjun Tu, Qichao Zhang, Ke Chen, Dongbin Zhao |
| 1042 | Learning to explore when mistakes are not allowed | Charly Pecqueux-Guézénec, Stephane Doncieux, Nicolas Perrin-Gilbert |
| 267 | Stochastic $k$-Submodular Bandits with Full Bandit Feedback | Guanyu Nie, Vaneet Aggarwal, Christopher John Quinn |
| 586 | Practical Comparisons of Reservoir Topology Performance and Input Distribution in Digital Reservoir Computers | Lewis Thelen, Vikram Ravindra |
| 869 | Agential AI for Integrated Continual Learning, Deliberative Behavior, and Comprehensible Models | Zeki Doruk Erden, Boi Faltings |
| 557 | Predictive Improvement through Latent Space Optimisation | Alexander McCaffrey, Eduardo Alonso, Esther Mondragon |
| 862 | Decision-Making in Evolving Environments: A Bayesian Multi-Agent Bandit Framework | Mohammad ESSA Alsomali, Leandro Soriano Marcolino, Barry Porter, Roberto Rodrigues-Filho |
| 253 | Negotiated Reasoning: On Provably Addressing Relative Over-Generalization | Junjie Sheng, Wenhao Li, Bo Jin, Hongyuan Zha, Jun Wang, Xiangfeng Wang |
| 202 | Regret Guarantees for a UCB-based Algorithm for Volatile Combinatorial Bandits | Andra Siva Sai Teja, Kumar Abhishek, Sujit Gujar, Yadati Narahari, Ganesh Ghalme |
| 1163 | Open-World Classification with Bayesian Gaussian Mixture Models | Justin Clarke, Przemyslaw A. Grabowicz, David Jensen |
| 263 | On the Effective Horizon of Inverse Reinforcement Learning | Yiqing Xu, Finale Doshi-Velez, David Hsu |
| 1386 | Uncertainty-Aware Opponent Modeling for Deep Reinforcement Learning | Likun Yang, Pei Xu, Shiyue Cao, Yongjian Ren, Xiaotang Chen, Kaiqi Huang |
| 149 | Goal Recognition via Variational Causality | Jiaqi Wen, Leonardo Rosa Amado |
| 213 | Hypothesis-Driven Explainable Goal Recognition | Abeer Alshehri, Hissah Alotaibi, Tim Miller, Mor Vered |
| 455 | Game-Theoretic Goal Recognition in Time-Sensitive Applications | Sara Bernardini, Fabio Fagnani, Santiago Franco |
| 1338 | Towards Efficient Online Goal Recognition through Deep Learning | Lorenzo Serina, Mattia Chiari, Alfonso Gerevini, Luca Putelli, Ivan Serina |
| 1319 | Beyond Goal Recognition: A Reinforcement Learning-based Approach to Inferring Agent Behaviour | Sheryl Mantik, Michael Dann, Minyi Li, Huong Ha, Julie Porteous |
| 1070 | DECAF: Learning to be Fair in Multi-agent Resource Allocation | Ashwin Kumar, William Yeoh |
| 1208 | 𝛽-DQN: Improving Deep Q-Learning By Evolving the Behavior | Hongming Zhang, Fengshuo Bai, Chenjun Xiao, Chao Gao, Bo Xu, Martin Müller |
COINE (14)
| ID | Title | Authors |
|---|---|---|
| 108 | Gricean Norms as a Basis for Effective Collaboration | Fardin Saad, Pradeep K. Murukannaiah, Munindar P. Singh |
| 363 | On the Complexity of Learning to Cooperate in Populations of Socially Rational Agents | Saptarashmi Bandyopadhyay, Mustafa Mert Çelikok, Robert Loftin |
| 29 | Enhancing Graph-based Coordination with Evolutionary Algorithms for Episodic Multi-agent Reinforcement Learning | Kexing Peng, Pengyi Li, Jianye Hao |
| 607 | Bottom-Up Reputation Promotes Cooperation with Multi-Agent Reinforcement Learning | Tianyu Ren, Xuan Yao, Yang Li, Xiao-Jun Zeng |
| 943 | Voter Model Meets Rumour Spreading: A Study of Consensus Protocols on Graphs with Agnostic Nodes | Marcelo Matheus Gauy, Anna Abramishvili, Eduardo Colli, Tiago Madeira, Frederik Mallmann-Trenn, Vinícius Franco Vasconcelos, David Kohan Marzagao |
| 1034 | Uncertain Machine Ethics Planning | Simon Kolker, Louise A. Dennis, Ramon Fraga Pereira, Mengwei Xu |
| 436 | Model and Mechanisms of Consent for Responsible Autonomy | Anastasia S. Apeiron, Davide Dell’Anna, Pradeep K. Murukannaiah, Pinar Yolum |
| 351 | The Road to Inequality is Paved with Good Intentions | Lihi Idan |
| 755 | Model of the influence of external signals on the trust of the agent in Multi Agent System | Frederique Lalieu, Tomasz Zurek, Tom van Engers |
| 971 | Combining Normative Ethics Principles to Learn Prosocial Behaviour | Jessica Woodgate, Nirav Ajmeri |
| 547 | Reasoning and Planning with Dynamic Social Norms | Taylor Olson, Roberto Salas-Damian, Kenneth Forbus |
| 588 | Dynamic Reward Sharing to Enhance Learning in the Context of Multiagent Teams | Kyle Tilbury, David Radke |
| 1104 | Symplex: Learning social norm hierarchies by combining autonomous exploration and expert imitation | Oliver Deane, Oliver Ray |
| 1022 | Generalised BDI Planning | Felipe Meneguzzi, Ramon Fraga Pereira, Nir Oren |
ROBOT (12)
| ID | Title | Authors |
|---|---|---|
| 580 | Planning, scheduling, and execution on the Moon: the CADRE technology demonstration mission | Gregg Rabideau, Joseph A. Russino, Andrew Branch, Nihal N. Dhamani, Tiago Vaquero, Steve Chien, Jean-Pierre de la Croix, Federico Rossi |
| 567 | Adaptive Bi-Level Multi-Robot Task Allocation and Learning under Uncertainty with Temporal Logic Constraints | Xiaoshan Lin, Roberto Tron |
| 1385 | Together We Rise: Optimizing Real-Time Multi-Robot Task Allocation using Coordinated Heterogeneous Plays | Aritra Pal, Anandsingh Chauhan, Mayank Baranwal |
| 643 | Value Iteration for Learning Concurrently Executable Robotic Control Tasks | Sheikh A. Tahmid, Gennaro Notomista |
| 738 | Monte Carlo Tree Search with Velocity Obstacles for safe and efficient motion planning in dynamic environments | Lorenzo Bonanni, Daniele Meli, Alberto Castellini, Alessandro Farinelli |
| 1139 | Discovery and Deployment of Emergent Robot Swarm Behaviors via Representation Learning and Real2Sim2Real Transfer | Connor Mattson, Varun Raveendra, Ricardo Vega, Cameron Nowzari, Daniel S. Drew, Daniel S. Brown |
| 867 | OGS-SLAM: Hybrid ORB-Gaussian Splatting SLAM | Xiaohan Li, Wenxiang Shen, Dong Liu, Jun Wu |
| 5 | PANDA: Priority-Based Collision Avoidance Framework for Heterogeneous UAVs Navigating in Dense Airspace | Gamdeep Singh, Jaskirat Singh, Sujit PB |
| 906 | Distributed Adaptive Macroscopic Ensemble Task Allocation of Heterogeneous Robot Teams in Dynamic Environments | Victoria Edwards, M. Ani Hsieh |
| 747 | Multi-Agent Pickup and Delivery with Batteries | Marcello Bavaro, Francesco Amigoni |
| 452 | Compensating latent nonlinear dynamics for practical consensus control | Krzysztof Kowalczyk, Dominik Baumann, Cristian R. Rojas, Paweł Wachel |
| 362 | Enhancing Robot Navigation Policies with Task-Specific Uncertainty Management | Gokul Puthumanaillam, Paulo Padrao, Jose Fuentes, Leonardo Bobadilla, Melkior Ornik |
Poster Session 6 (PS6): May 23 Afternoon
Date & Time: Friday, May 23, 3:15PM – 4:00PM
Total number of posters: 63
GTEP (19)
| ID | Title | Authors |
|---|---|---|
| 727 | Asymptotic Existence of Class Envy-free Matchings | Tomohiko Yokoyama, Ayumi Igarashi |
| 907 | Computing Efficient and Envy-Free Allocations under Dichotomous Preferences using SAT | Ari Conati, Andreas Niskanen, Ronald de Haan, Matti Järvisalo |
| 28 | Game-Theoretically Secure Distributed Protocols for Fair Allocation in Coalitional Games | T-H. Hubert Chan, Qipeng Kuang, Quan Xue |
| 24 | Order Symmetry: A New Fairness Criterion for Assignment Mechanisms | Rupert Freeman, Geoffrey Pritchard, Mark C. Wilson |
| 174 | Probably Correct Optimal Stable Matching for Two-Sided Market Under Uncertainty | Andreas Athanasopoulos, Anne-Marie George, Christos Dimitrakakis |
| 1062 | On the Gale-Shapley Algorithm for Stable Matchings with a Partial Honesty Nash Refinement | James Patrick Bailey, Craig Tovey |
| 31 | Approximating One-Sided and Two-Sided Nash Social Welfare With Capacities | Salil Gokhale, Harshul Sagar, Rohit Vaish, Jatin Yadav |
| 394 | Harmonious Balanced Partitioning of a Network of Agents | Pulkit Agarwal, Harshvardhan Agarwal, Vaibhav Raj, Swaprava Nath |
| 521 | Timed Obstruction Logic: A Timed Approach to Dynamic Game Reasoning | James Ortiz, Vadim Malvone, Jean Leneutre |
| 1396 | Changing the Rules of the Game: Reasoning About Dynamic Phenomena in Multi-Agent Systems | Rustam Galimullin, Maksim Gladyshev, Munyque Mittelmann, Nima Motamed |
| 530 | Rational Capability in Concurrent Games | Yinfeng Li, Emiliano Lorini, Munyque Mittelmann |
| 169 | Causes and Strategies in Multiagent Systems | Sylvia S. Kerkhove, Natasha Alechina, Mehdi Dastani |
| 937 | Bidding Games on Markov Decision Processes with Quantitative Reachability Objectives | Guy Avni, Martin Kurečka, Kaushik Mallik, Petr Novotný, Suman Sadhukhan |
| 1109 | Game of Thoughts: Iterative Reasoning in Game-Theoretic Domains with Large Language Models | Benjamin Kempinski, Ian Gemp, Kate Larson, Yoram Bachrach, Marc Lanctot, Tal Kachman |
| 837 | From Natural Language to Extensive-Form Game Representations | Shilong Deng, Yongzhao Wang, Rahul Savani |
| 500 | Tackling Temporal Deontic Challenges with Equilibrium Logic | Davide Soldà, Pedro Cabalar, Agata Ciabattoni, Emery A. Neufeld |
| 134 | Neighborhood Stability in Assignments on Graphs | Haris Aziz, Grzegorz Lisowski, Mashbat Suzuki, Jeremy Vollen |
| 433 | Egalitarianism in Online Coalition Formation | Saar Cohen, Noa Agmon |
| 1210 | Matching Markets with Chores | Thorben Tröbst, Jugal Garg, Vijay Vazirani |
LEARN (30)
| ID | Title | Authors |
|---|---|---|
| 973 | Hierarchical Imitation Learning of Team Behavior from Heterogeneous Demonstrations | Sangwon Seo, Vaibhav V. Unhelkar |
| 441 | A Minimax-Bayes Approach to Ad Hoc Teamwork | Victor Villin, Thomas Kleine Buening, Christos Dimitrakakis |
| 43 | ReSCOM: Reward-Shaped Curriculum for Efficient Multi-Agent Communication Learning | Xinghai Wei, Tingting Yuan, Jie Yuan, Dongxiao Liu, Xiaoming Fu |
| 331 | Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning | Bidipta Sarkar, Warren Xia, Karen Liu, Dorsa Sadigh |
| 442 | Networked Agents in the Dark: Team Value Learning under Partial Observability | Guilherme S. Varela, Alberto Sardinha, Francisco S. Melo |
| 207 | Nucleolus Credit Assignment for Effective Coalitions in Multi-agent Reinforcement Learning | Yugu Li, Zehong Cao, Jianglin Qiao, Siyi Hu |
| 468 | Learning with Limited Shared Information in Multi-agent Multi-armed Bandit | Junning Shao, Siwei Wang, Zhixuan Fang |
| 201 | Multi-agent Multi-armed Bandits with Minimum Reward Guarantee Fairness | Piyushi Manupriya, Himanshu, SakethaNath Jagarlapudi, Ganesh Ghalme |
| 98 | MacLight: Multi-scene Aggregation Convolutional Learning for Traffic Signal Control | Sunbowen Lee, Hongqin Lyu, Yicheng Gong, Sun Yingying, Chao Deng |
| 375 | FGLight: Learning neighbor-level information for Traffic Signal Control | Hang Xiao, Huale Li, Shuhan Qi, Jiajia Zhang, DingZhong Cai |
| 966 | Reinforcement Learning-based Approach for Vehicle-to-Building Charging with Heterogeneous Agents and Long Term Rewards | Fangqi Liu, Rishav Sen, Jose Paolo Talusan, Ava Pettet, Aaron Kandel, Yoshinori Suzue, Ayan Mukhopadhyay, Abhishek Dubey |
| 712 | Tackling Sparsity in Designated Driver Dispatch with Multi-Agent Reinforcement Learning | Jiaxuan Jiang, Ling Pan, Lin Zhou, Longbo Huang, Zhixuan Fang |
| 338 | Tackling Uncertainties in Multi-Agent Reinforcement Learning through Integration of Agent Termination Dynamics | Somnath Hazra, Pallab Dasgupta, Soumyajit Dey |
| 63 | Multi-agent reinforcement learning in the all-or-nothing public goods game on networks | Benedikt Valentin Meylahn |
| 1374 | MOSMAC: A Multi-agent Reinforcement Learning Benchmark on Sequential Multi-Objective Tasks | Minghong Geng, Shubham Pateria, Budhitama Subagdja, Ah-Hwee Tan |
| 644 | FedHPD: Heterogeneous Federated Reinforcement Learning via Policy Distillation | Wenzheng Jiang, Ji Wang, Xiongtao Zhang, Weidong Bao, Cheston Tan, Flint Xiaofeng Fan |
| 949 | Trading-off Accuracy and Communication Cost in Federated Learning | Mattia Jacopo Villani, Emanuele Natale, Frederik Mallmann-Trenn |
| 1090 | Diverse Heterogeneous Graph Conditioned Diffusion for Multi-Agent Teaming | Luis Manuel Pimentel, Sean Charles Ye, James Ellis Grant Pagan, Matthew Gombolay |
| 505 | Reducing Variance Caused by Communication in Decentralized Multi-agent Deep Reinforcement Learning | Changxi Zhu, Mehdi Dastani, Shihan Wang |
| 1154 | Evaluating and Improving Graph-based Explanation Methods for Multi-Agent Coordination | Siva Kailas, Shalin Jain, Harish Ravichandar |
| 978 | Towards Fair and Efficient Policy Learning in Cooperative Multi-Agent Reinforcement Learning | Umer Siddique, Peilang Li, Yongcan Cao |
| 722 | SFedRec: A Federated Learning Framework for Dynamic Session-based Recommendation | Hexiao Zhang, Yanni Tang, Jiamou Liu, Wu Chen |
| 732 | Efficient Training of Generalizable Visuomotor Policies via Control-Aware Augmentation | Yinuo Zhao, Kun Wu, Tianjiao Yi, Zhiyuan Xu, Zhengping Che, Chi Harold Liu, Jian Tang |
| 317 | CADP: Towards Better Centralized Learning for Decentralized Execution in MARL | Yihe Zhou, Shunyu Liu, Yunpeng Qing, Tongya Zheng, Kaixuan Chen, Jie Song, Mingli Song |
| 826 | Bidirectional Distillation: A Mixed-Play Framework for Multi-Agent Generalizable Behaviors | Lang Feng, Jiahao Lin, Dong Xing, Li Zhang, De Ma, Gang Pan |
| 1395 | A Minimalist Approach to Augmentation-based Self-supervised Representation Learning for On-policy Reinforcement Learning | Nasik Muhammad Nafi, William Hsu |
| 565 | Knowledge Transfer in Model-Based Reinforcement Learning Agents for Efficient Multi-Task Learning | Dmytro Kuzmenko, Nadiya Shvai |
| 17 | Dynamic Option Creation in Option-Critic Reinforcement Learning | Mateus Begnini Melchiades, Gabriel de Oliveira Ramos, Bruno Castro da Silva |
| 1384 | Context Adaptive Memory-Efficient LLM Inference for Edge Multi-Agent Systems | Hamza Mohammed, Sai Chand Boyapati, Hang Yin |
| 782 | Integrating Large Language Models with Reinforcement Learning for Generalization in Strategic Card Games | Wannian Xia, Meng Fang, Zihao Guo, Yali Du, Bo Xu |
COINE/EMAS (14)
| ID | Title | Authors |
|---|---|---|
| 1107 | Reputation-Filtered Reward Reshaping: Encouraging Cooperation in High Dimensional Semi-Cooperative Multi-agent Settings | Hassan Raissouni, Wissal Bekhti, Btissam El Khamlichi, Amal Seghrouchni |
| 1351 | The effect of agent-based feedback on prosociality in social dilemmas | Jennifer Renoux, Filipa Correia, Joana Campos, Lucas Morillo-Mendez, Neziha Akalin, Fernando P. Santos, Ana Paiva |
| 798 | Predictability Awareness for Efficient and Robust Multi-Agent Coordination | Rom√°n Chiva Gil, Daniel Jarne Ornia, Khaled A. Mustafa, Javier Alonso-Mora |
| 301 | Near-Linear Time Leader Election in Multiagent Networks | Ajay Kshemkalyani, Manish Kumar, Anisur Rahaman Molla, Gokarna Sharma |
| 1038 | Robustness of Epistemic Gossip Protocols Against Data Loss | Yoshikatsu Kobayashi, Koji Hasebe |
| 1390 | Responsible Uplift Modeling | Lihi Idan, Ming Li |
| 47 | Azorus: Commitments over Protocols for BDI Agents | Amit K. Chopra, Matteo Baldoni, Samuel H. Christie V, Munindar P. Singh |
| 499 | The Many Challenges of Human-Like Agents in Virtual Game Environments | Maciej Świechowski, Dominik Slezak |
| 992 | Large Language Models for Virtual Human Gesture Selection | Parisa Ghanad Torshizi, Laura B. Hensel, Ari Shapiro, Stacy Marsella |
| 1153 | On Some Fundamental Problems for Multi-Agent Systems Over Multilayer Networks | Daniel Rosenkrantz, Madhav Marathe, Zirou Qiu, S. S. Ravi, Richard Stearns |
| 929 | Practical Abstractions for Model Checking Continuous-Time Multi-Agent Systems | Yan Kim, Wojciech Jamroga, Wojciech Penczek, Laure Petrucci |
| 311 | IBGP: Imperfect Byzantine Generals Problem for Zero-Shot Robustness in Communicative Multi-Agent Systems | Yihuan Mao, Yipeng Kang, Peilun Li, Ning Zhang, Wei Xu, Chongjie Zhang |
| 113 | Local Anomaly Detection with Partial Observation in Multi-agent Systems as a Data Matching Game | Zixin Ye, Christopher Leckie, Tansu Alpcan |
| 75 | Efficient Model Checking with Semantically-Equivalent Models for vGOAL | Yi Yang, Tom Holvoet |